HDFS详解
HDFS详解
HDFS概述
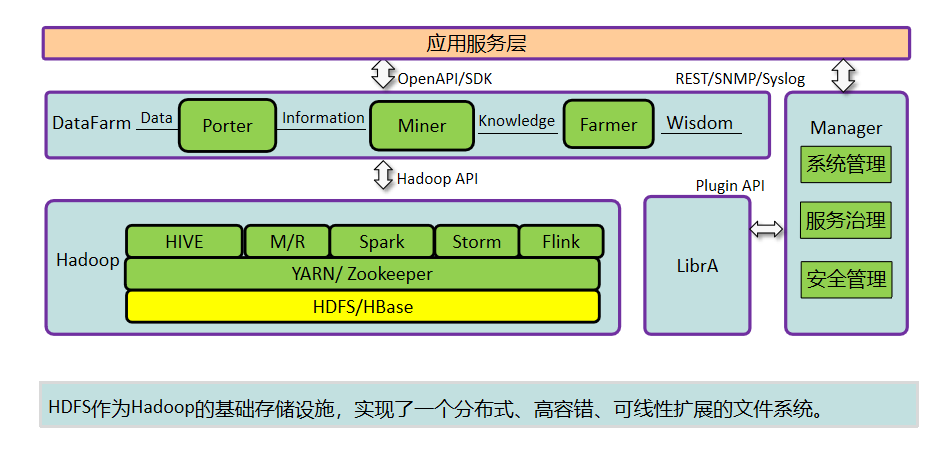
Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用 FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪一种,需要看我们具体的实现类,在我们实际工作中,用到的最多的就是HDFS(分布式文件系统)以及LocalFileSystem(本地文件系统)了。
HDFS(Hadoop Distributed File System)是 Hadoop 项目的一个子项目。是 Hadoop 的核心组件之一, Hadoop 非常适于存储大型数据 (比如 TB 和 PB),其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件,并且提供统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统。
HDFS特性
1.命名空间:HDFS使用一个层次化的命名空间来管理文件和目录,类似于Linux中的文件系统。
2.数据块:HDFS采用了块存储机制,将大文件切分成多个大小相等的块,每个块都被复制到多个节点上,从而保证了数据的可靠性和可用性。
3.数据流:HDFS中的数据是以流的形式进行传输的,这样可以保证数据的高效性和可靠性。
4.权限控制:HDFS支持基于ACL的权限控制机制,可以对文件和目录进行细粒度的权限控制。
5.快照:HDFS支持文件和目录的快照功能,可以在文件修改后快速恢复到之前的状态,从而保证数据的完整性和可靠性。
6.可插拔性:HDFS支持多种存储介质,包括本地磁盘、SAN和NAS等,可以根据不同的应用场景选择不同的存储介质。
HDFS优点
高可靠性:HDFS使用了多副本机制,数据被自动复制到多个节点上,即使某个节点失效,数据也能够保持完整性和可用性。
高容错性:HDFS采用了块(Block)存储机制,数据被切分成多个块,每个块被复制到多个节点上,即使某个节点失效,仍然能够从其他节点上获取数据块,从而保证了数据的可用性。
高可扩展性:HDFS能够处理海量数据,支持PB级别的数据存储和处理。
适合大数据分析:HDFS可以高效地处理海量数据,并且可以与Hadoop生态系统中的其他组件(如MapReduce和Spark)结合使用,进行大数据分析和处理。
可用于多种应用场景:除了大数据分析,HDFS还可用于其他应用场景,如日志收集、数据备份、图片存储等。
HDFS缺点
不适合小文件:HDFS的块大小默认为128MB,因此对于小文件的存储效率较低。同时,由于小文件较多,也会增加NameNode的负担,降低系统的性能。
不支持高并发写入:由于HDFS采用了多副本机制,需要进行复制和同步操作,因此对于高并发写入的场景,HDFS的性能会有所降低。
不支持实时数据处理:由于HDFS采用了批量处理机制,因此对于实时数据处理的场景,HDFS的响应时间较长。
下面给出一个HDFS的示例,假设我们有一个1TB大小的文件需要存储到HDFS上。首先,我们需要将这个文件切分成128MB大小的块,然后将每个块存储到HDFS上。由于HDFS采用了多副本机制,默认情况下会将每个块复制到3个节点上,因此总共需要存储3TB的数据。当需要读取这个文件时,HDFS会自动将多个块组合起来,并返回完整的文件数据。
在实际应用中,HDFS已经被广泛应用于各种领域,如大数据分析、机器学习、人工智能等。HDFS的优缺点需要根据实际情况进行权衡,在选择HDFS作为数据存储方案时,需要考虑数据的大小、读写频率、系统的可扩展性和容错性等因素,以确定是否适合使用HDFS作为数据存储方案。
HDSF架构
HDFS是一个主从体系结构,它由四部分组成,分别是HDFS Client、NameNode、DataNode以及Seconary NameNode
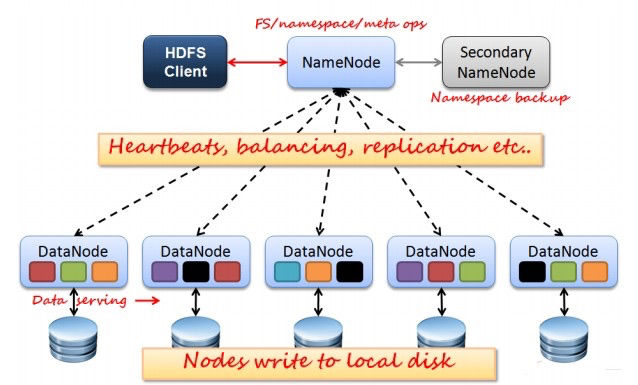
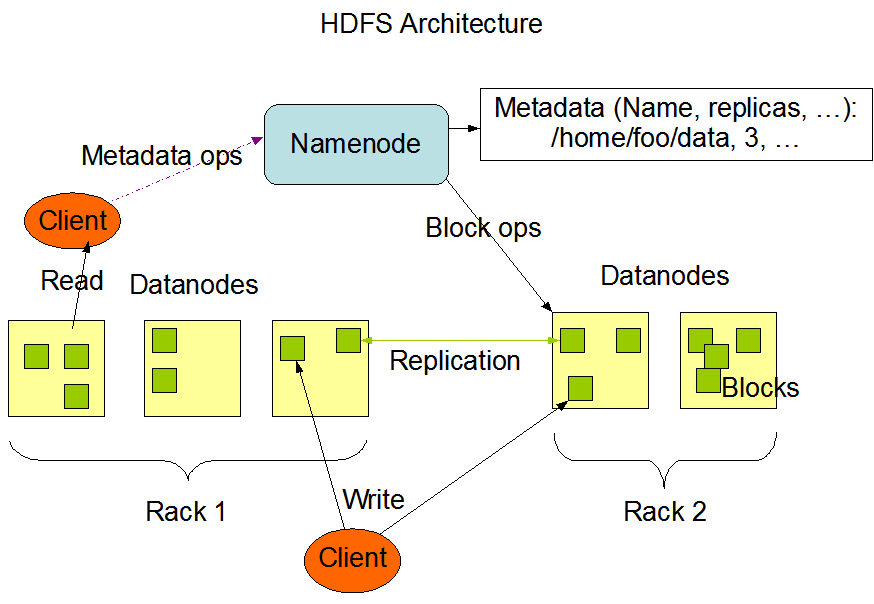
Client
支持业务访问HDFS,从NameNode ,DataNode获取数据返回给业务。多个实例,和业务一起运行
NameNode
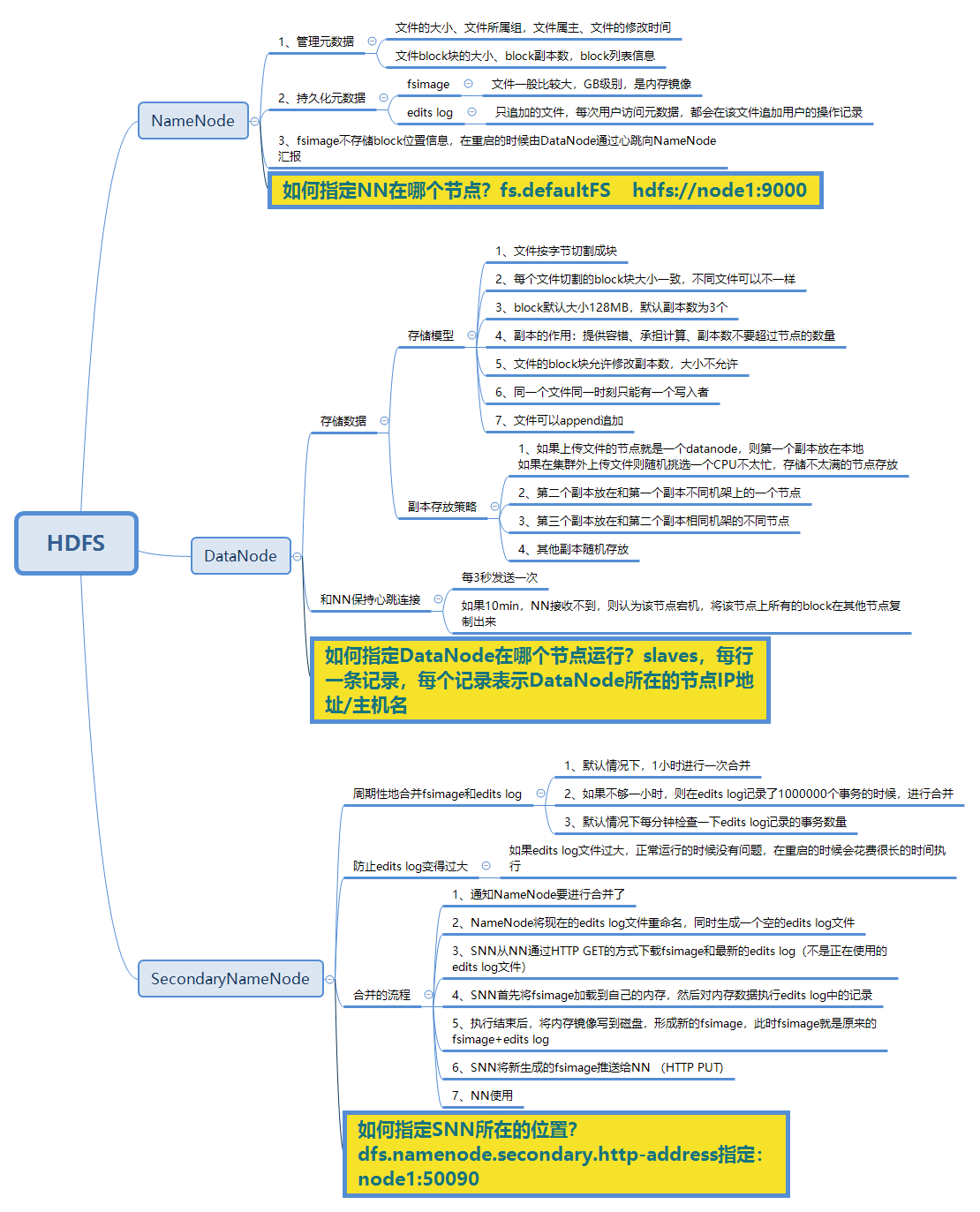
它是维护和管理 Datanode 的主守护进程;
它记录存储在集群中的所有文件的元数据,例如 block 的位置、文件大小、权限、层次结构等。有两个文件与元数据关联:
- FsImage:它包含自 Namenode 开始以来文件的 namespace 的完整状态;
- EditLogs:它包含最近对文件系统进行的与最新 FsImage 相关的所有修改。
它记录了发生在文件系统元数据上的每个更改。例如,如果一个文件在 HDFS 中被删除,Namenode 会立即在 EditLog 中记录这个操作。
它定期从集群中的所有 Datanode 接收心跳信息和 block 报告,以确保 Datanode 处于活动状态;
它保留了 HDFS 中所有 block 的记录以及这些 block 所在的节点;
它负责管理所有 block 的复制;
在 Datanode 失败的情况下,Namenode 会为副本选择新的 Datanode,平衡磁盘使用并管理到 Datanode 的通信流量。
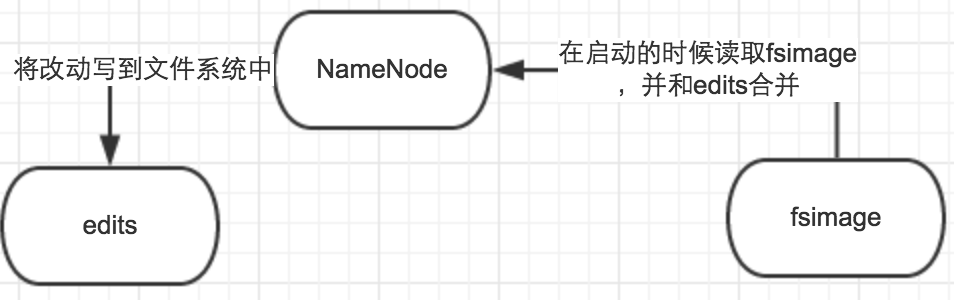
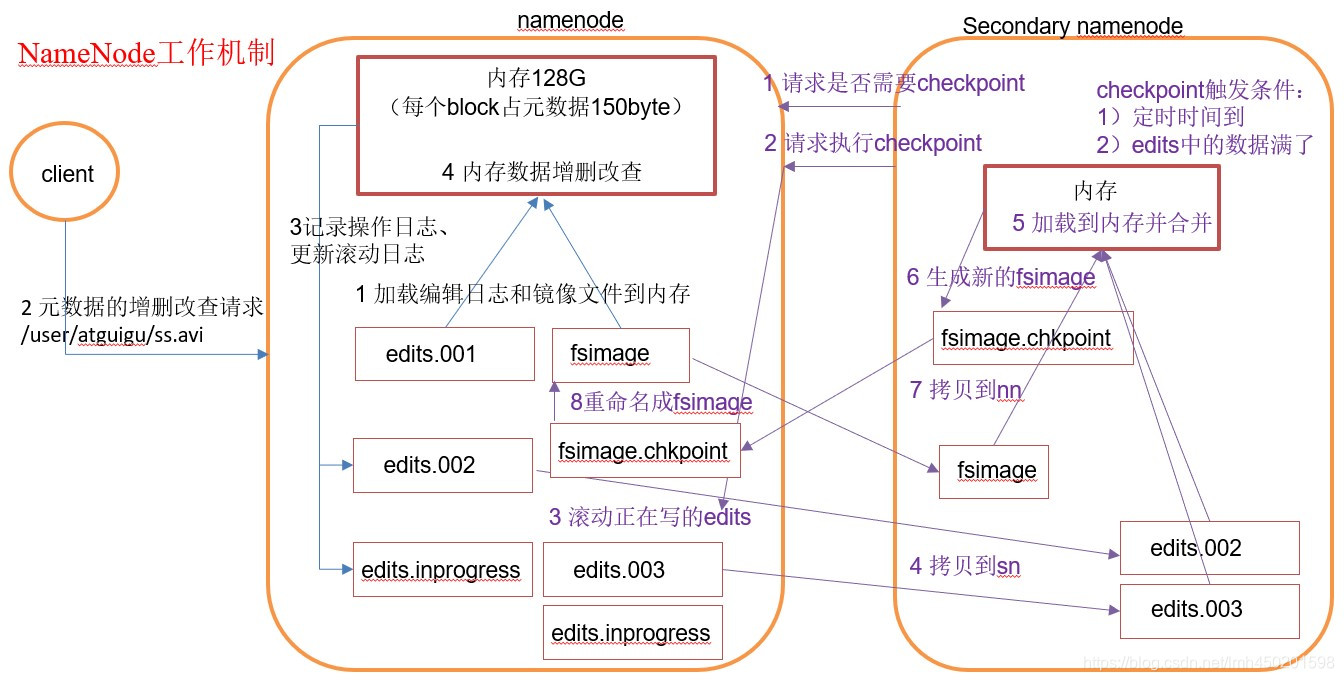
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。如下图所示:
运行中的NameNode有如下所示的目录结构:
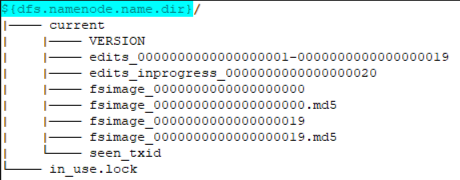
VERSION文件 :是一个Java属性文件,其中包含正在运行的HDFS的版本信息
编辑日志(edits log) :文件系统客户端执行写操作时,这些事务首先被记录到edits中。NameNode在内存中维护文件系统的元数据;当被修改时,相关元数据信息也同步更新。内存中的元数据可支持客户端的读请求。
命名空间镜像文件(fsimage):文件系统元数据的持久检查点,每个fsimage文件包含文件系统中的所有目录和文件inode的序列化信息(从Hadoop-2.4.0起,FSImage开始采用Google Protobuf编码格式),每个inodes表征一个文件或目录的元数据信息以及文件的副本数、修改和访问时间等信息。数据块存储在DataNode中,但fsimage文件并不描述DataNode。
seen_txid文件 :该文件对于NameNode非常重要,它是存放transactionId的文件,format之后是0,它代表的是NameNode里面的edits_*文件的尾数,NameNode重启的时候,会按照seen_txid的数字,循序从头跑edits_000*01~到seen_txid的数字。当hdfs发生异常重启的时候,一定要比对seen_txid内的数字是不是你edits最后的尾数,不然会发生建置NameNode时元数据信息缺失,导致误删DataNode上多余block。
in_use.lock文件 :是一个锁文件,NameNode使用该文件为存储目录加锁。可以避免其他NameNode实例同时使用(可能会破坏)同一个存储目录的情况。
Secondary NameNode
从字面上看,很容易会把Secondary NameNode当作备份节点;其实,这是一个误区,我们不能从字面来理解,阅读官方文档,我们可以知道,其实并不是这么回事。
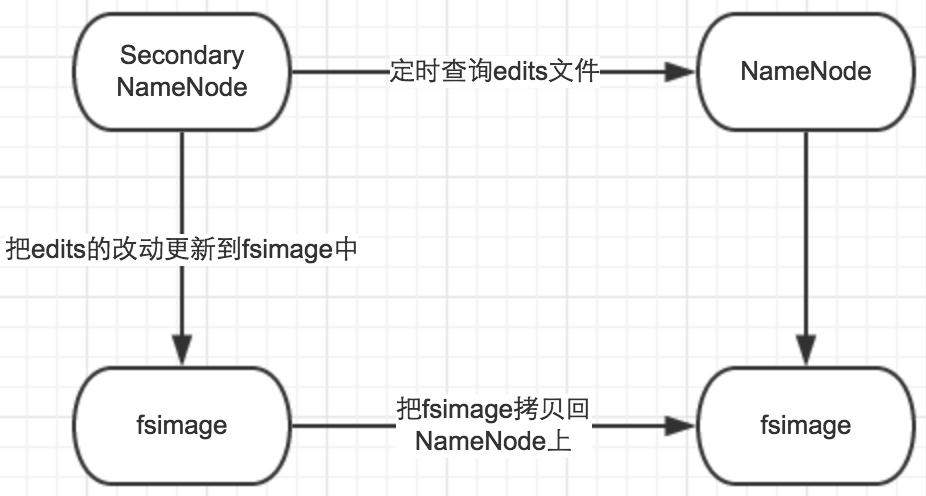
SecondaryNameNode是一个辅助的NameNode,不能代替NameNode。它的主要作用是用于合并FsImage和editlog文件。在没有SecondaryNameNode守护进程的情况下,从namenode启动开始至namenode关闭期间所有的HDFS更改操作都将记录到editlog文件,这样会造成巨大的editlog文件,所带来的直接危害就是下次启动namenode过程会非常漫长。
在启动SecondaryNameNode守护进程后,每当满足一定的触发条件(每3600s、文件数量增加100w等),SecondaryNameNode都会拷贝namenode的fsimage和editlog文件到自己的目录下,首先将fsimage加载到内存中,然后加载editlog文件到内存中合并fsimage和editlog文件为一个新的fsimage文件,然后将新的fsimage文件拷贝回namenode目录下。并且声明新的editlog文件用于记录DFS的更改。
DataNode
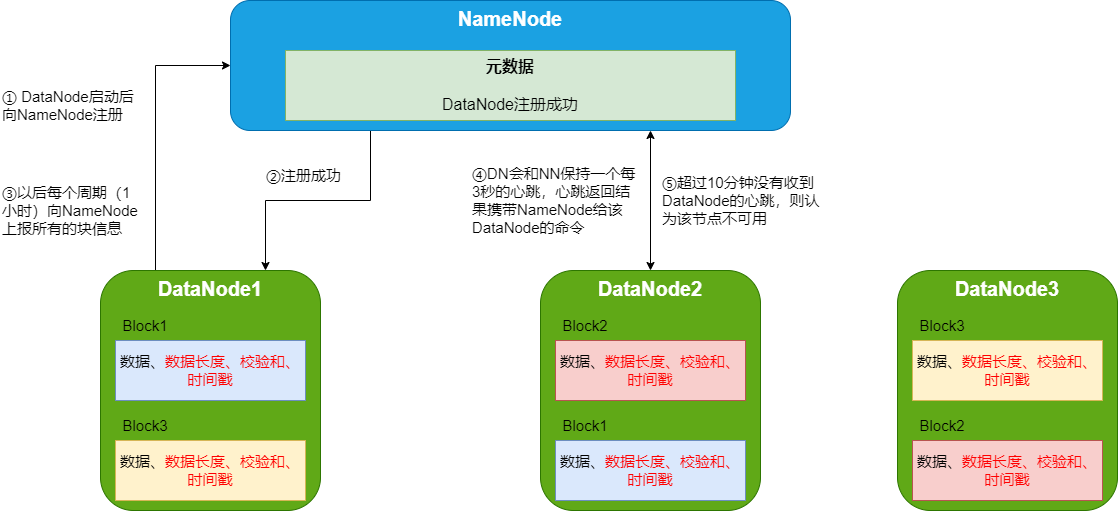
Datanode 是 HDFS 中的从节点,它是实际存储业务数据的节点。与 Namenode 不同的是,Datanode 是一种商品硬件,它并不具有高质量或高可用性。Datanode 是一个将数据存储在本地文件 ext3 或 ext4 中的 block 服务器。
一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
集群运行中可以安全加入和退出一些机器。
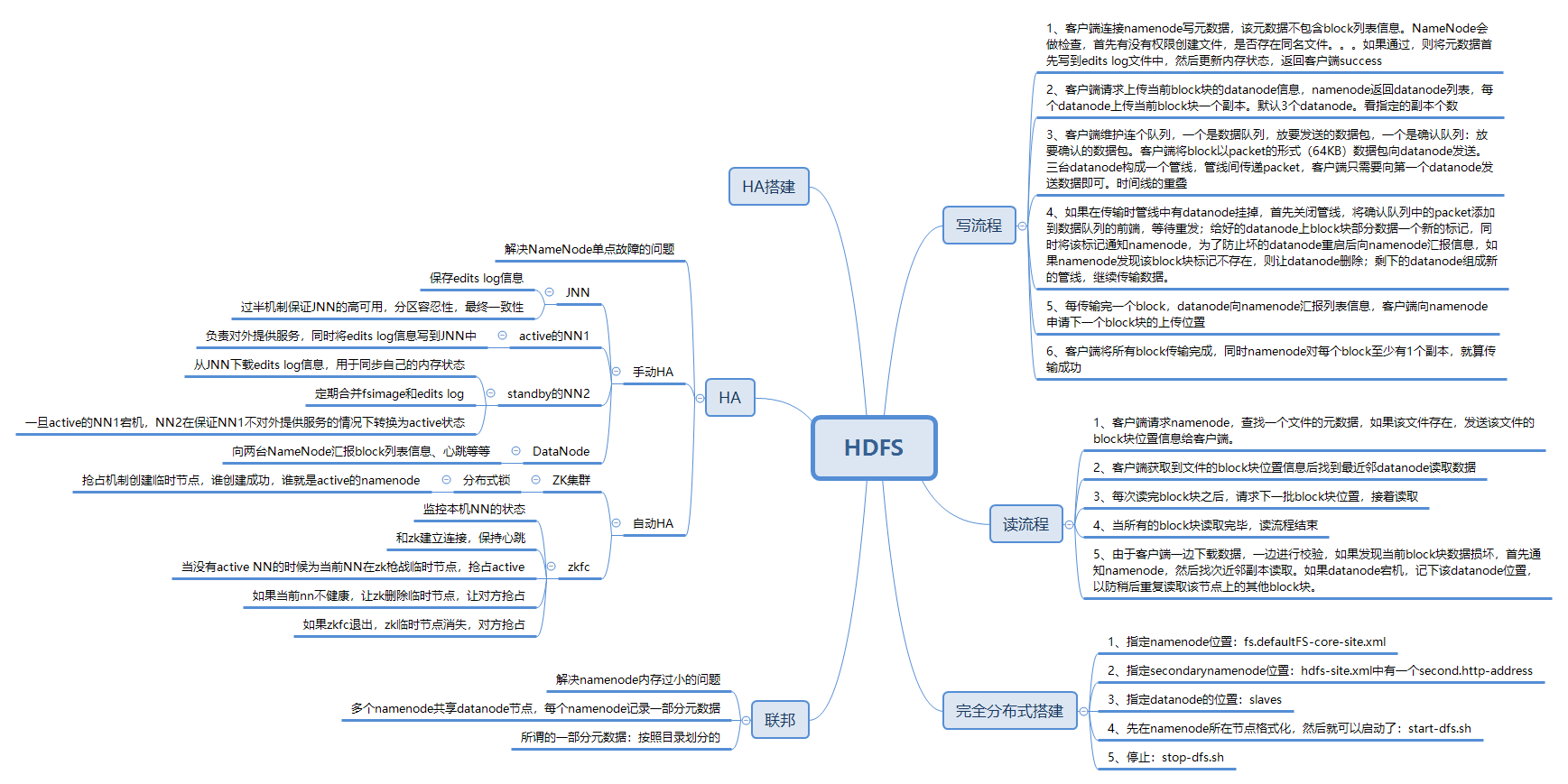
HDFS数据写入流程
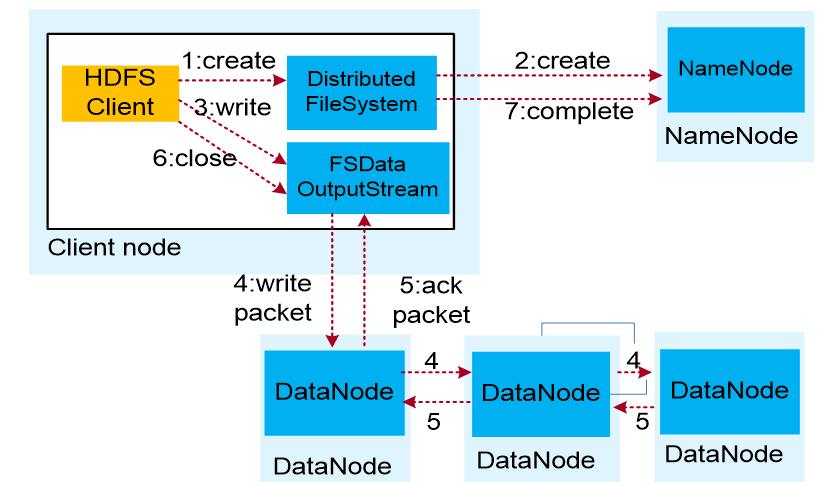
- 业务应用调用HDFS Client提供的API,请求写入文件。
- HDFS Client联系NameNode,NameNode在元数据中创建文件节点。
- 业务应用调用write API写入文件。
- HDFS Client收到业务数据后,从NameNode获取到数据块编号、位置信息后,联系DataNode,并将需要写入数据的DataNode建立起流水线。完成后,客户端再通过自有协议写入数据到DataNode1,再由DataNode1复制到DataNode2, DataNode3。
- 写完的数据,将返回确认信息给HDFS Client。
- 所有数据确认完成后,业务调用HDFS Client关闭文件。
- 业务调用close, flush后HDFS Client联系NameNode,确认数据写完成,NameNode持久化元数据。
HDFS数据读取流程
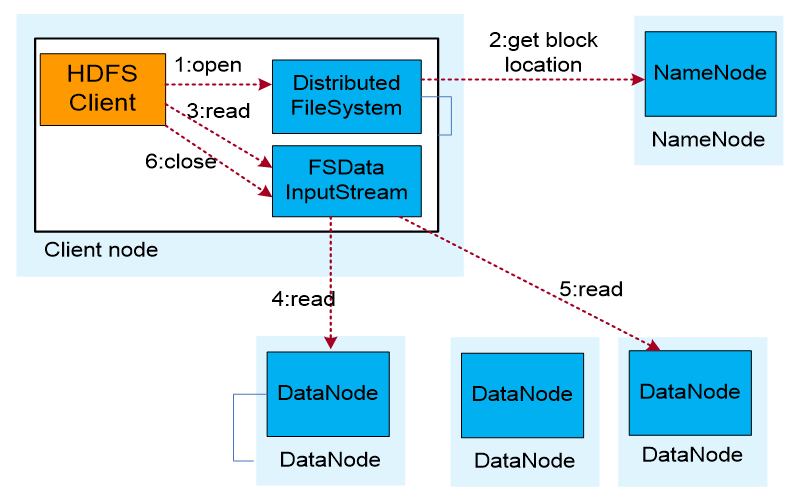
- 业务应用调用HDFS Client提供的API打开文件。
- HDFS Client联系NameNode,获取到文件信息(数据块、DataNode位置信息)。
- 业务应用调用read API读取文件。
- HDFS Client根据从NameNode获取到的信息,联系DataNode,获取相应的数据块。(Client采用就近原则读取数据)。
- HDFS Client会与多个DataNode通讯获取数据块。
- 数据读取完成后,业务调用close关闭连接。
蚂蚁🐜再小也是肉🥩!
“您的支持,我的动力!觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付